
Dar respuesta a qué es Docker no es tarea baladí. Si nos atenemos a su definición en la Wikipedia: “Docker es un proyecto de código abierto que automatiza el despliegue de aplicaciones dentro de contenedores de software, proporcionando una capa adicional de abstracción y automatización de Virtualización a nivel de sistema operativo en Linux”. Sin embargo, esta definición a día de hoy necesita matización, pues está incompleta.
Desde hace unos años alrededor de este motor se ha ido construyendo todo un ecosistema, añadiendo funcionalidades, atomizando las existentes para hacerlo más portable y ampliando su alcance. Tal es así que en la actualidad Docker Inc mantiene más de 20 proyectos que abarcan desde la coordinación de contenedores para ayudar al desarrollador hasta la orquestación de grandes clusters distribuidos, sin olvidarnos de "la fontanería" necesaria para construir sobre ella aplicaciones y plugins que amplíen este ecosistema. Y es que Docker adopta la filosofía “batteries included but interchangeables”, es decir, te ofrezco mis herramientas pero puedes usar las tuyas propias o añadir funcionalidades a las existentes mediante plugins.
Entonces, ¿qué es Docker? Un poco de historia
En marzo de 2013 la empresa dotCloud libera un motor de contenedores para Llinux muy ligero que hace uso de la librería LXC. Tras el éxito de las primeras versiones la compañía decide centrar sus esfuerzos en este producto y cambia su nombre a Docker Inc.
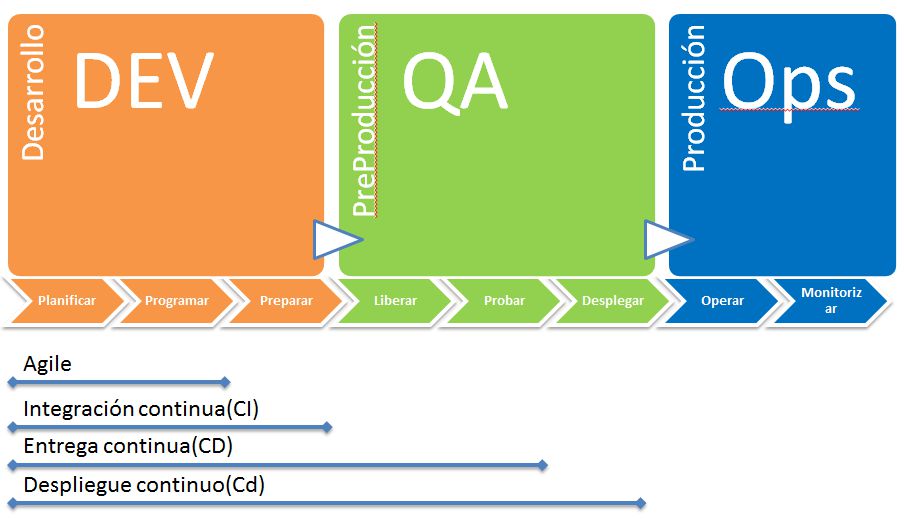
Tras unos meses decide crear su propia librería escrita en Go, eliminar la necesidad de parchear el Kernel y crear herramientas alrededor de su motor. Tras una campaña exitosa de financiación y conseguir colaboraciones muy importante por parte de Red Hat, IBM, Microsoft, Ubuntu o Google, la empresa empieza a crear un vasto ecosistema de aplicaciones alrededor de este motor. En la actualidad en prácticamente todas las etapas del ciclo de vida de una aplicación podemos usar alguna de sus herramientas:
Muchas empresas son recelosas del rápido éxito que está cosechando esta tecnología y no ven con buenos ojos que una sola empresa tenga el control absoluto con lo que empiezan a aparecer alternativas que fragmentan el mercado. Esto hace que afloren incompatibilidades entre tecnologías de contenedores. Para atajar este problema Docker Inc decide ceder el control del runtime de contenedores RunC a la fundación OCI y actualmente ContainerD se encuentra en trámites de pasar a formar parte de una organización de software libre. Cabe destacar que todos los proyectos (salvo las herramientas comerciales) están liberadas baja la licencia Apache 2.0 y el código está disponible en GitHub. Además construye todo el sistema de cañerías (plumbing) para que terceros puedan crear productos y plugins usando su base tecnológica sin generar incompatibilidades.
Un momento, ¿Docker solo está disponible para Llinux entonces?
No. Dado el auge de los contenedores, Microsoft llega a un acuerdo con la compañía y decide incorporar esta tecnología a su sistema operativo. Podemos usar contenedores nativos Docker con Kernel Windows en Windows 2016 y Wwndows 10 aniversary edition. Además Microsoft es el mayor contribuyente al código tras Docker Inc y ha firmado acuerdos para garantizar que Docker se ejecute correctamente en sus sistemas ya sea nativamente o usando Kernel Linux mediante virtualización (hyper-V). También da soporte en Azure a nivel de IaaS, PaaS y Web App.
Contenedores vs. máquinas virtuales
Quien se acerca por primera vez a Docker tiende a pensar que es una especie de máquinas virtuales ligeras o una suerte de aplicaciones empaquetadas, pero el concepto dista bastante de estas soluciones. En primer lugar no existe un hipervisor que virtualice hardware y sobre la que se despliegue un sistema operativo completo y se cree un elenco de dispositivos virtuales. En Docker lo que haremos es usar las funcionalidades del Kernel para encapsular (contenerizar) un sistema. De esta manera este contenedor tendrá su propio árbol de procesos, sus propios interfaces de red, su propio subsistema, etc. De tal forma que la aplicación que corra dentro de él no sabrá que está en un contenedor. Los contenedores están aislados entre sí y podemos limitar los recursos que utilizará (RAM, CPU, ancho de banda, i/o de disco, etc.). A todos los efectos se comportarán como máquinas independientes.
Además iniciar un contenedor tiene un impacto muy liviano. A diferencia de las máquinas virtuales o físicas no es necesario iniciar un sistema operativo completo con sus chequeos y arranque de procesos iniciales que hacen que demandan en la fase inicial i/o de disco, CPU y RAM hasta que el sistema se estabiliza. Usando contenedores la demanda de recursos se limitará al consumo de la aplicación que resida dentro. Poner en ejecución un contenedor es cuestión de milisegundos.
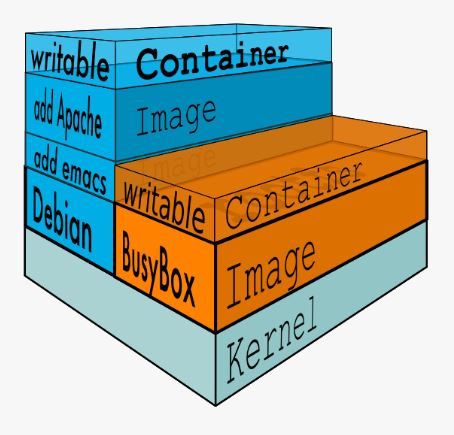
La segunda ventaja viene dada por el sistema de imágenes. Un contenedor no es más una imagen puesta en ejecución a la que otorgamos recursos. Estas imágenes están compuestas por capas de solo lectura a las que se le añade una capa superior de escritura que perdurará sólo mientras el contenedor está en ejecución. En la construcción de la imagen se crea una capa por cada cambio que hagamos, de tal forma que si imaginamos una aplicación que corra que corra sobre jboss podríamos simplificar que tendríamos las siguientes capas:
- Sistema operativo base
- Jboss
- Nuestra aplicación
 ¿Qué ventaja aporta esto?
¿Qué ventaja aporta esto? La más evidente es un ahorro de espacio en disco: Si ejecutamos 100 instancias de un mismo contenedor solo tendremos una copia de las capas inferiores (aunque se creará una capa de escritura para cada contenedor que será eliminada cuando el contenedor se destruya). Además si ejecutamos contenedores distintos pero que comparten capas nos ocurrirá lo mismo (Ej: base de datos, backend, frontend que comparten java y el mismo S.O.).
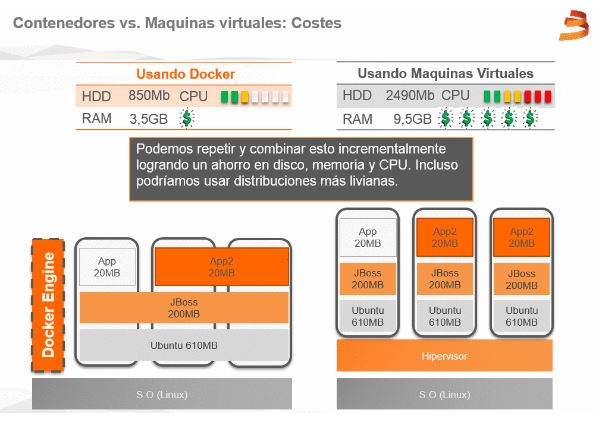
Esto indirectamente aporta otras ventajas como que el sistema operativo host puede habilitar técnicas de cacheo de disco que beneficiará a todos los contenedores en ejecución que accedan a ese contenido.
También el sistema de actualizaciones es más sencillo, rápido y directo. Tenemos un sistema de repositorios (Registry) donde residen las imágenes que podemos gestionar desde el cliente. Comparado con las máquinas virtuales no es necesario descargar la imágen completa sino solo las capas que hayan cambiado. Frente a herramientas de gestión de la configuración como Puppet, Chef o Ansible, no tendremos que esperar a que se apliquen sus políticas, se actualicen los paquetes necesarios... en cada instancia, sino que lo haremos una única vez y todos los contenedores que se pongan en ejecución o se actualicen tendrán esos cambios. Esto nos permite realizar despliegues de una forma muy rápida y ordenada sin perder peticiones en el proceso (si usamos orquestadores como Swarm, Mesos o Kubernetes).
Hay que pensar que nuestra imagen contiene todo y solo lo necesario para ejecutar la aplicación que reside dentro de él. No necesitamos librerías, ejecutables, módulos o drivers de los que nuestra aplicación no haga uso con lo cual el tamaño es más contenido que en un sistema completo, es decir, una imagen es autocontenida y nos garantiza que se ejecutará igual en cualquier host que tenga el engine de Docker, ya sea el portátil de un desarrollador, una máquina virtual o la nube.
La seguridad a un nivel básico se mejora de varias maneras: Las buenas prácticas de Ddocker indican que solo un proceso debe correr por contenedor, esto implica una menor exposición de procesos y un menor número componentes ofrece menos “superficie” en la que buscar exploits o realizar ataques. Las capas además están identificadas por un hash que se genera en función de su contenido, lo que garantiza la integridad de estas. Y si aún necesitamos más confianza podemos habilitar el firmado de las imágenes. También podemos llevar prácticas como la infraestructura inmutable al extremo y poner en ejecución contenedores en solo lectura que no permitan escrituras en ellos imposibilitando que en una intrusión se inyecte código.
Docker, aunque es una tecnología con pocos años de vida, se sustenta sobre estándares con más de 20 años de antigüedad. La tecnología de contenedores forma parte de Llinux desde 2008 y es equiparable a proyectos anteriores como Solaris Zones o BSD Jails. Se apoya además funcionalidades nativas del Kernel como Cgroups, Namespaces, Iptables o IPVS.
Al final
todo esto se traduce en una reducción de costes de manera directa por la necesidad de menos recursos para ejecutar nuestros servicios e indirectamente por la agilidad que introduce en todo el ciclo de vida permitiendo desarrollar, probar y desplegar más rápido con el consiguiente reducción del time to market.
BENEFICIOS CLAVE DE DOCKER










